
N + 1 문제란
연관 관계가 설정된 엔티티를 조회할 경우 조회된 데이터의 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 된다.
이를 N+1문제라고 한다.
실제 발생하는 경우를 살펴보자.
package com.test.test;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
@Getter
@Setter
@NoArgsConstructor
public class Board {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(mappedBy = "board", fetch = FetchType.EAGER)
private List<Comments> commentList = new ArrayList<>();
}package com.test.test;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.*;
@Entity
@Getter
@Setter
@NoArgsConstructor
public class Comments {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String content;
@ManyToOne
private Board board;
public Comments(Board board) {
this.board = board;
}
}
- 하나의 게시판의 여러 개의 댓글이 달린다.
- 댓글은 하나의 게시판에 종속되어 있다.
게시판을 조회해보자.
게시판 10개 생성 댓글 10개 생성 한 게시글에 댓글 10개
@Test
void exampleTest() {
List<Comments> commentList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
commentList.add(new Comments("com" + i));
}
commentsRepository.saveAll(commentList);
List<Board> boardList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Board board = new Board("board" + i);
board.setCommentList(commentList);
boardList.add(board);
}
boardRepository.saveAll(boardList);
em.clear();
System.out.println("====================================================================");
List<Board> boardLists = boardRepository.findAll();
}
게시판 조회 쿼리 호출을 하면 댓글 조회 쿼리가 게시판을 조회한 row만큼 쿼리가 호출된다.
FetchType.EAGER 전략 때문이라 생각할 수 있는데 LAZY로 바꾸게 된다면 연관관계 데이터를 프록시 객체로 바인딩한다는 의미다.
실제 Board title을 직접 조회하게 된다면 쿼리가 나가기 때문에 LAZY로 바꿔도 N+1 문제와는 큰 연관이 없다.
FetchType를 바꾸는 것은 연관관계 데이터를 사용하는 시점으로 미룰지, 아니면 초기에 한꺼번에 다 가져올지 차이만 있다.
그럼 N+1은 왜 발생이 되는가?
N+1 문제가 발생하는 이유는 JPA가 JPQL을 분석해서 SQL을 생성할 때는 글로벌 Fetch 전략을 참고하지 않고 오직 JPQL 자체만을 사용한다.
해결방안
1. fetch join
JPQL을 사용하여 DB에서 데이터를 가져올 때 처음부터 연관된 데이터까지 같이 가져오게 하는 방법이다.
나는 select * from board left join comments on comments.board_id = board.id 이 쿼리가 나오길 기대하고, 이 최적화된 쿼리를 내가 직접 사용할 수 있는 방법이 fetch join이다.
하지만 fetch join은 JPARepository에서 제공해주지 않으므로 JPQL로 직접 작성해야 한다.
@Query("select b from Board b join fetch b.commentList")
List<Board> findAllFetchJoin();
실제 쿼리가 INNER JOIN 으로 호출되는 것을 알 수 있다.
연관관계가 있을 경우 하나의 쿼리로 한방에 다 가져오므로 N + 1문제가 일어나지 않는다.
2. @BatchSize

하이버네이트가 제공하는 org.hibernate.annotations.BatchSize 어노테이션을 이용하면 연관된 엔티티를 조회할 때 지정된 size 만큼 SQL의 IN절을 사용해서 조회한다.
@BatchSize가 있으면 Board의 건수만큼 SQL을 날리지 않고, 조회한 Board 의 id들을 SQL IN 절로 한번에 날린다.
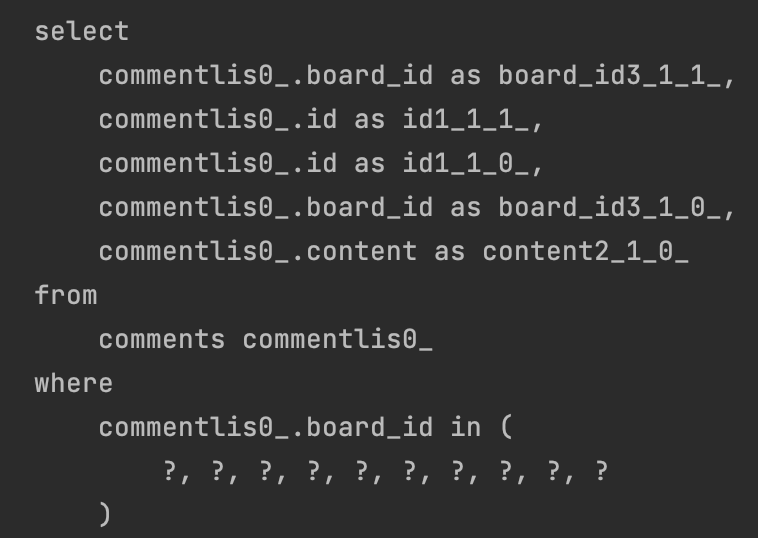
만약 1000개가 넘게 된다면 위 in절이 한 번 더 나갈 것이다.
'스프링' 카테고리의 다른 글
| 스프링 시큐리티 내부 흐름 (1) | 2023.12.18 |
|---|---|
| 스프링 DI (0) | 2023.12.17 |
| DTO매핑을 해야하는 이유 (0) | 2023.11.13 |
| 스프링 부트 핵심가이드 9장 (0) | 2023.04.07 |
| 스프링 부트 핵심 가이드 5장 (0) | 2023.04.04 |