
이번 프로젝트에서는 패키징과 기본 설정 및 entity 클래스 정의 등을 맡게 되었다.
평소처럼 연관관계가 필요한 컬럼에는 @ManyToOne과 @JoinColumn으로 외래키를 지정해 주었다.
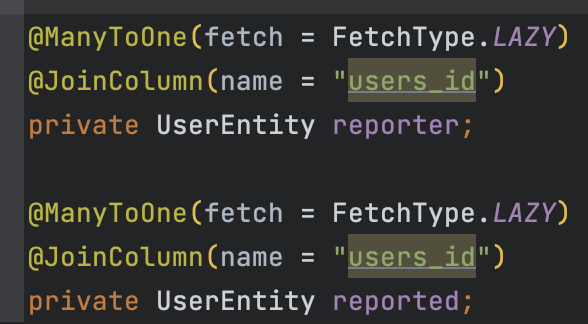
모든 entity를 정의하고 나서 테이블과 컬럼이 잘 생성되는지 테스트겸 ddl = create로 설정해두고 서버를 실행했는데
Caused by: org.hibernate.MappingException: Column 'users_id' is duplicated in mapping for entity 에러가 떳다.
먼저 직역을 해보면 users_id가 중복되어 매핑되었다고 한다.
생각해보면 데이터베이스랑 1:1매핑을 해주기 때문에 당연한 일인데 패키징에 집중하다보니 놓치고 있었다.
또한 @JoinColumn의 name속성에 대해 잘못알고 있었다.
먼저 잘못알고 있었던 @JoinColumn의 name 속성은 연관된 테이블의 pk값을 지정해주는 거로 알고있었다.
하지만 name 속성은 연관된 테이블의 pk값과 매핑시킬 현재 테이블에서 생성될 외래 키 컬럼의 이름을 지정해주는 것이다.
즉, 현재 테이블에서 어떤 이름으로 외래 키를 생성할지를 결정하는 속성이다.
조금 더 자세히 들어가 보면 @JoinColumn에는 referencedColumnName이라는 속성이 존재한다.
referencedColumnName은 따로 지정해주지 않으면 자동으로 연관된 테이블의 pk값을 지정해준다.
(이 말은 내가 지정만 해 준다면 연관된 테이블의 pk가 아닌 다른 컬럼과도 매핑시킬 수 있다.)
그래서 이때까지 프로젝트에서는 현재 테이블이 대상 테이블의 pk값과 매핑시킬 외래키는 한 개밖에 없었기 때문에 따로 문제가 되지 않았다.
이제 알게된 방법으로 @JoinColumn의 값을 바꿔보았다

이렇게 바꿔주면 에러가 발생하지않고 잘 실행이 된다.
그런데 위 글에서 "referencedColumnName은 따로 지정해주지 않으면 자동으로 연관관계가 있는 테이블의 pk값을 지정해준다"라는 말을 했기때문에 지우고 다시 실행해보자.


실행도 잘되고 내가 예상했던 컬럼명대로 잘 생성이 된 걸 알 수 있다.
'개발' 카테고리의 다른 글
| EC2 젠킨스 빌드 멈춤 상황 해결과정에서 깨달은 CI/CD툴 선택 (0) | 2025.03.12 |
|---|---|
| HandlerInterceptor 사용하여 권한체크 (0) | 2024.12.21 |
| ansible 기본 실행 옵션 (1) | 2024.10.04 |
| 네이버 클라우드 Jenkins를 활용한 배포 자동화 (1) | 2024.07.25 |
| 공통 검증 메서드 모듈화 및 메서드 분리 (0) | 2024.07.25 |