

MongoDB 선택 이유
우리 프로젝트의 게시판은 질문과 답변이 비슷하지만 서로 다른 데이터 구조를 가지고 있다.
질문 작성 시 저장되는 필드
qnaId, language, title, content, nickname, viewCount, answerCount, isAdopted, createDate
답변 작성 시 저장되는 필드
answerId, nickname, profileImage, createDate, content, replyCount, likeCount, isSelected, isLike
질문과 답변이 유사한 구조지만 실제로는 서로 다른 필드들을 사용하기 때문에 MongoDB의 스키마 유연성이 적합하다고 판단했습니다.
RDB와 MongoDB 비교
만약 MariaDB를 사용했다면 Question과 Answer로 테이블을 분리해야 했을 것이다.
이 경우에는 두 테이블에서 공통적으로 필요한 필드들을 관리하기 위해 부모 게시판 테이블을 만들거나 각 테이블에 중복된 컬럼을 둬야 한다. 또한 질문과 답변을 함께 조회할 때마다 JOIN 연산이 필수이고, 새로운 필드가 추가된다면 스키마 변경 작업이 복잡해질 수도 있다.
반면 MongoDB는 단일 컬렉션으로 질문과 답변을 통합 관리할 수 있고, 사용하지 않는 필드는 아예 저장하지 않아 효율적입니다. parentId로 계층 구조 표현도 자연스럽게 가능하고, 새로운 필드를 추가할 때도 스키마 변경 없이 바로 확장이 가능하다.
현재 프로젝트에서 MongoDB 사용 시 문제점
프로젝트 진행 중 다음과 같은 고민을 했다.
아무리 스키마가 유연하다지만, 한 개의 도큐먼트에 모든 필드를 관리하면 유지보수도 힘들고 가독성도 너무 떨어지지 않나?
이럴 거면 차라리 MariaDB가 더 나았을 거 같은데 라는 생각이 들었다.
단일 도큐먼트
public class BoardDocument extends BaseTimeDocument {
@Id
private String id;
private Long userId;
private String nickname;
private String profileImg;
private String title;
private String content;
private String language;
private String parentId;
private Long likeCount;
private Long viewCount;
private Long answerCount;
private Long replyCount;
private boolean isBlind;
private boolean isSelected;
}실제 사용했던 도큐먼트 이고, 단일 도큐먼트에서 게시판 관련 모든 필드를 관리했을 때 다음과 같은 성능 문제가 발견됐다.
- 조회수 1 증가만으로 모든 도큐먼트를 다시 저장해야 된다.
- 트래픽이 몰리면 몰린 트래픽 만큼의 MongoDB에 부하가 발생한다.
- 통계 업데이트가 자주 일어난다.
개선 방안
정규화 후 MariaDB 사용
도큐먼트 필드를 Question과 Answer 두 테이블로 분리하는 방식이다.
정규화를 거치기 때문에 테이블 크기가 작아지고, RDB 특징인 트랜잭션을 보장받게 된다
하지만 JOIN이 많아져 복잡해지고 answerCount 같은 집계 데이터를 매번 COUNT(*)로 계산하면 성능이 떨어진다.
또한 이미 MongoDB기반으로 운영되고 있어, MariaDB로 전환한다면 데이터 정합성 문제가 발생 할 수 있다.
도큐먼트 분리
도큐먼트를 분리하게 되면 Board와 BoardStats로 분리하게 된다.
이렇게 분리하면 새로운 통계 필드가 추가되면 BoardStats에만 추가하면 되기 때문에 확장성도 챙길 수 있다.
또한 통계 관련 로직을 별도 서비스로 분리할 수 있고, 배치 처리나, 캐싱 전략 등을 독립적으로 적용할 수 있다.
최종 결정 : 도큐먼트 분리
두 방안 모두 결국 통계 데이터의 잦은 업데이트 문제를 근본적으로 해결하려면 Redis 캐싱이 필요하다.
이때 MongoDB 분리 방식이 더 유리하다고 판단했습니다.
가장 큰 이유는 통계 정보만을 캐싱할 것인데, MongoDB 사용 시 통계 필드만 분리한 BoardStats 도큐먼트를 별도로 캐싱하면 되므로, 직렬화나 JOIN 없이도 통계 데이터를 효율적으로 관리할 수 있다.
반면 MariaDB는 게시글과 답변 등 여러 테이블이 연관돼 집계 처리에 JOIN과 COUNT 연산이 필요하고, 정규화된 데이터를 비정규화해야되기 때문에 구조가 복잡해진다.
도큐먼트 분리
자주 변경되는 통계 데이터를 별도 도큐먼트로 분리했다.
public class BoardStatsDocument {
@Id
private String qnaId;
private Long likeCount;
private Long viewCount;
private Long answerCount;
private Long replyCount;
}
BoardDocument는 본문 중심의 필드만 관리하게 했다.
public class BoardDocument extends BaseTimeDocument {
@Id
private String id;
private Long userId;
private String nickname;
private String profileImg;
private String title;
private String content;
private String language;
private String parentId; // 게시글이라면 존재하지 않고 답변이라면 존재
private boolean isBlind;
private boolean isSelected; // 답변이 채택된 답변인지 확인
private boolean isAdopted; // 게시글에 채택된 답변이 있는지 확인
}
isAdopted 필드 추가 이유
기존에는 질문에 채택된 답변이 있는지 확인하기 위해 추가 Aggregation 쿼리를 수행해야 했습니다.
하지만 lookup 과정으로 인해 응답 속도 저하와 쿼리 복잡도를 유발했습니다.
이런 고민을 isAdopted 필드 하나만 추가하면 해소가 가능하여 채택 여부를 명시적으로 관리하도록 변경했습니다.
Redis 도입
도큐먼트 분리 이후, 게시글을 조회할 때마다 통계 정보를 함께 조회해야만 했습니다.
상세 조회에서는 문제가 없지만, 전체 조회에서는 데이터가 많아질수록 성능 저하와 N+1 문제가 발생할 수 있습니다.
이를 해결하기 위해 MongoDB의 Aggregation과 Redis 캐시를 도입을 결정했습니다.
서비스 계층 리팩토링
기존 코드

기존에는 MongoRepository의 기본 메서드에 의존하여 복잡한 조회 로직을 처리하기 어려웠습니다.
개선 코드
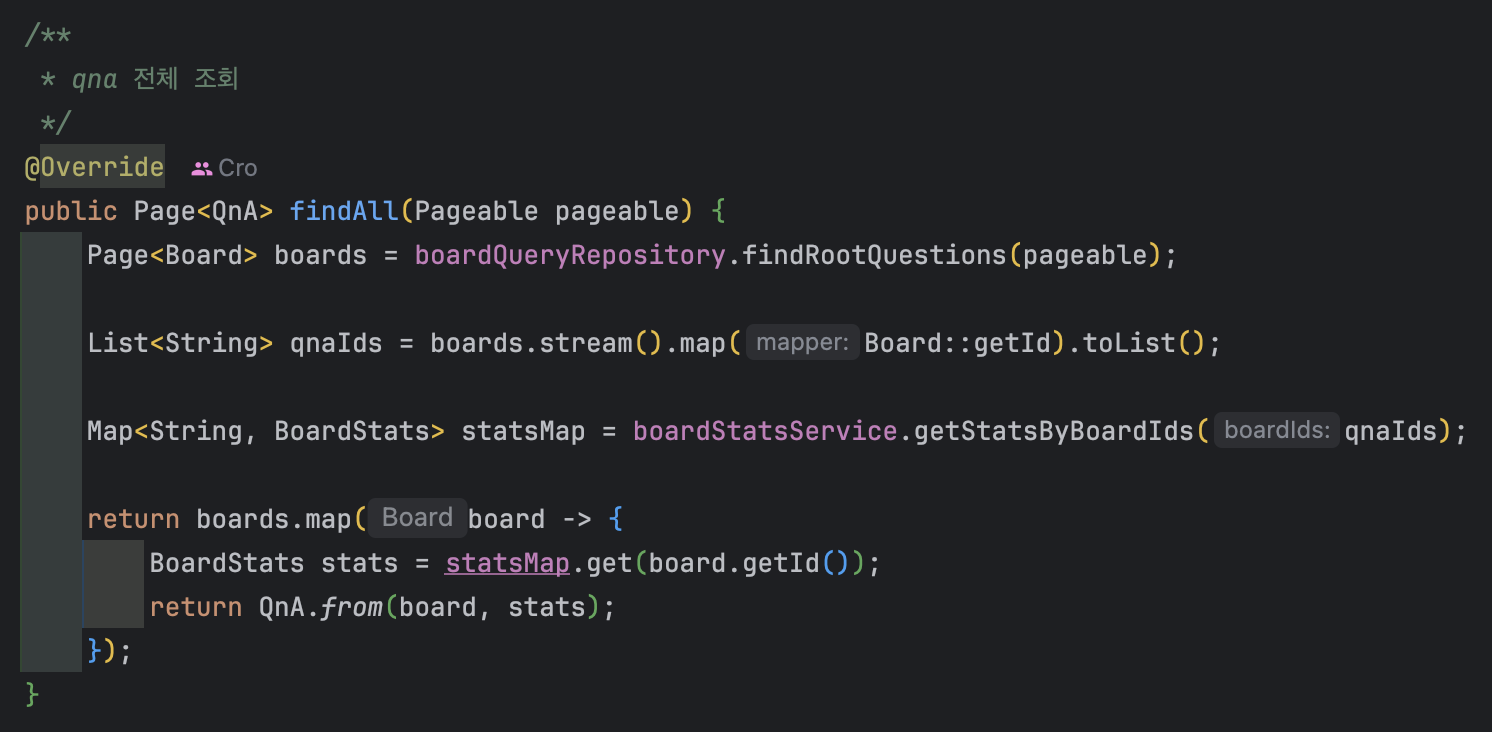
개선 후에는 게시글을 먼저 가져온 후 게시글에 맞는 통계 정보를 가져오도록 했습니다.
이 과정에서 캐싱과 Aggregation을 사용하였습니다.
핵심 구현 로직
Aggregation을 활용해 게시글 조회 최적화
public Page<BoardDocument> findRootQuestions(Pageable pageable) {
Criteria criteria = Criteria.where("parentId").exists(false)
.and("isBlind").is(false); // 블라인드 제외
Aggregation aggregation = newAggregation(
match(criteria),
sort(pageable.getSort().isEmpty() ? Sort.by(Sort.Order.desc("createDate")) : pageable.getSort()),
skip(pageable.getOffset()),
limit(pageable.getPageSize())
);
AggregationResults<BoardDocument> results =
mongoTemplate.aggregate(aggregation, "qna", BoardDocument.class);
List<BoardDocument> content = results.getMappedResults();
Query countQuery = new Query(criteria);
return PageableExecutionUtils.getPage(
content,
pageable,
() -> mongoTemplate.count(countQuery, BoardDocument.class)
);
}
두 개의 필터 조건(parentId, isBlind)을 효율적으로 처리하고, 향후 %lookup을 통한 조인이 필요할 수도 있기 때문에 Aggregation을 활용했습니다.
통계 데이터 캐싱 전략
서비스 계층의 책임 분리

BoardStats 관련 로직은 BoardStatsService 내부에서 관리하고, BoardQueryService에서는 게시글 본문 관련 로직에만 집중할 수 있도록 책임을 분리했습니다.
이를 통해 각 서비스가 자신의 도메인 로직만을 다루도록 하여 응집도를 높이고 유지보수성을 향상시켰습니다.
Repository 계층

캐시에서 데이터를 가져오는데 캐시에 데이터가 없을 경우 fallBack을 하기 위한 메서드입니다.
<fallBack은 이번에 캐싱하면서 알게된 개념인데 기존 설계가 실패하거나 누락되었을 때, 대체 로직을 두어 해결하는 전략이라고 합니다>
현재 상황에서는 Redis 캐시에서 1차 조회를 하고, 캐시에 없는 id들을 다시 findAllById를 통해 가져오는 방식입니다.
Redis 캐시 구현
public Map<String, BoardStats> getWithFallback(
List<String> qnaIds,
Function<List<String>, List<BoardStats>> fallback
) {
List<String> redisKeys = qnaIds.stream()
.map(id -> KEY_PREFIX + id)
.toList();
List<Object> cachedResults = redisTemplate.opsForValue().multiGet(redisKeys);
Map<String, BoardStats> resultMap = new HashMap<>();
List<String> missedQnaIds = new ArrayList<>();
for (int i = 0; i < qnaIds.size(); i++) {
Object cached = cachedResults.get(i);
String qnaId = qnaIds.get(i);
if (cached instanceof BoardStatsCacheDto statsCacheDto) {
resultMap.put(qnaId, statsCacheDto.toModel());
} else {
missedQnaIds.add(qnaId);
}
}
if (!missedQnaIds.isEmpty()) {
List<BoardStats> fallbackStats = fallback.apply(missedQnaIds);
for (BoardStats stats : fallbackStats) {
String key = KEY_PREFIX + stats.getQnaId();
BoardStatsCacheDto statsCacheDto = BoardStatsCacheDto.from(stats);
redisTemplate.opsForValue().set(key, statsCacheDto, CACHE_TTL, TimeUnit.SECONDS);
resultMap.put(stats.getQnaId(), stats);
}
}
return resultMap;
}
redisTemplate.opsForValue().multiGet(redisKeys)의 경우 N + 1 문제를 방지하기 위해 multiGet으로 일괄조회 하였습니다.
결과를 담을 Map과 캐시 미스된 id를 담을 List를 미리 선언하고, 캐시에 있으면 도메인 객체로 변환해서 resultMap에 담아주고 캐시에 없으면 missedQnaIds에 추가하여 fallBack 전략으로 처리하였습니다.
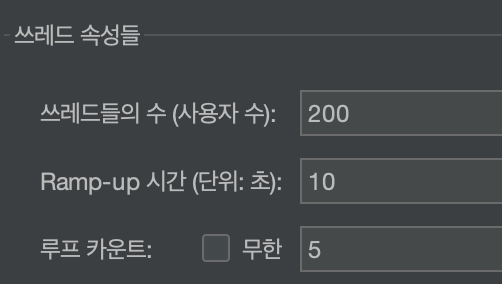
성능 비교 (JMeter 테스트)
테스트 조건
캐싱 적용 전 결과

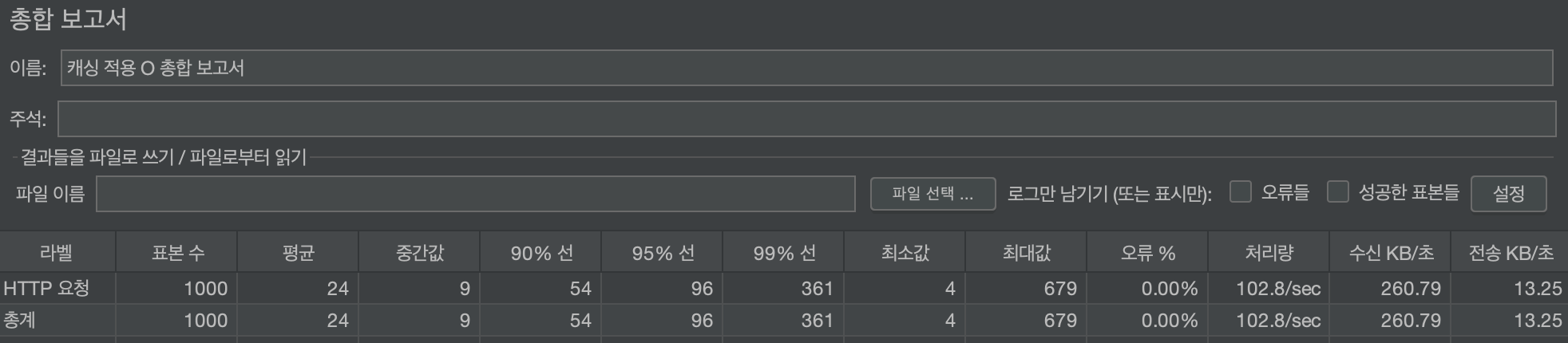
캐싱 적용 후 결과
결과
캐싱 적용으로 평균 응답 시간은 약 96% 감소되었습니다.
또한 처리량은 증가하였고, 전체적인 성능이 매우 향상된 것을 볼 수 있습니다.
특히 대용량 동시 요청 처리 상황에서도 안정성과 속도를 모두 확보할 수 있게 되었습니다.
'개발' 카테고리의 다른 글
| 개발 환경 통일을 위한 Docker Compose 도입 (5) | 2025.07.30 |
|---|---|
| Redis 캐시 구조 개선 : Redis Hash 적용하기 (1) | 2025.06.24 |
| Redis 캐싱 직렬화 실패 해결 과정 (LocalDateTime 대응) (2) | 2025.05.06 |
| 대형 Document 분리와 비지니스 로직 개선 중 발생한 성능이슈 : [MongoDB 성능 리팩토링] (1) | 2025.04.29 |
| OAuth2.0 로그인 성공시 토큰 관리 (0) | 2025.04.05 |