

현재 상황
재고 차감에 동시성 이슈가 있어서 비관락을 적용해 동시성 문제를 해결하였다.
하지만 비관적 락 특성상 락을 획득하고 있는 시간이 길어지면 다른 요청들이 대기 상태로 밀리면서 DB 커넥션 병목이 발생하고 실패율이 50%가 넘는 문제가 발생한 것을 확인했다.

실제로 지표를 확인해 보면, 가상 유저 수와 TPS가 각각 500명, 160 req/s까지 올라갔다가 약 15초 만에 급격히 감소하는 것을 볼 수 있다.
또한 재고 100개가 너무 빨리 소진되면서 나머지 시간은 의미 없는 409 응답만 반복됐다.
비관락 적용 과정은 재고 차감 시 발생하는 동시성 이슈 해결 - 비관적 락 에서 확인할 수 있습니다.
테스트 시나리오
기존 테스트는 재고가 빠르게 소진되어 성능 지표를 관찰하기 어려웠고, 지속적인 락 경합 상황을 만들기 위해 테스트 시나리오를 새로 구성했다.
500명의 사용자가 1분 동안 재고 10,000개를 차감하는 상황을 가정했다.
각 요청은 1개씩 차감하며, 락 경합이 지속되는 환경에서 응답 시간과 TPS, 병목 지점을 확인했다.
개선 목표
클라우드펀딩 플랫폼의 특성상 인기 밴드가 오픈되면 한정된 재고를 두고 다수의 사용자가 동시에 몰리는 상황이 발생한다.
비관적 락을 적용했을 때, DB 커넥션 부족으로 인해 실패율이 50~60%로 확인됐다.
절반의 사용자가 타임아웃이나 에러를 경험하며 재시도해야 하는 상황이었고, 이는 "이미 품절된 건 아닐까?"하는 불안감이 생기고 실제로 품절됐을 때 사용자 경험은 부정적으로 변한다.
따라서 응답 시간이 다소 느리더라도 대부분의 요청이 성공적으로 처리되는 것이 사용자 경험에 더 중요하다고 판단해, 실패율을 5% 이하로 낮추어 안정적인 서비스를 제공하는 것을 우선 목표로 생각했다. 또한 가능하면 TPS도 100 req/s를 달성하려고 한다.
이번 테스트는 로컬 환경에서 진행해 인프라 확장보다는 애플리케이션 레벨에서의 동시성 제어 개선에 집중했다.
import http from 'k6/http';
import { check } from 'k6';
import { Trend } from 'k6/metrics';
import { performanceThresholds } from '../../config/thresholds.js';
import { generateUUID } from '../../utils/uuid-generator.js';
/**
* Reward 서비스 - 재고 차감 성능 테스트
*
* 목적: 단계별 성능 개선 효과 측정
* 시나리오: 500명이 1분간 재고 10,000개를 차감 요청
*
* 테스트 단계:
* - baseline: 비관적 락 + HikariCP 기본 설정
* - hikaricp: HikariCP 튜닝 (pool-size 50) + 트랜잭션 최소화
* - redis: Redis 분산 락
*
* 실행 명령어 예시:
* - docker-compose run --rm k6 run \
* -e BASE_URL=http://host.docker.internal:18083 \
* -e TEST_DATA_ID=1027b841-a102-4047-ab01-bcb9a60b4476 \
* -e TEST_STAGE=redis \
* /scripts/services/reward/stock-reserve-performance-test.js
*/
export let options = {
vus: 500,
duration: '1m',
thresholds: performanceThresholds,
tags: {
test_stage: __ENV.TEST_STAGE || 'baseline',
},
};
const successDuration = new Trend('success_response_time');
const failDuration = new Trend('fail_response_time');
const BASE_URL = __ENV.BASE_URL || 'http://host.docker.internal:18083';
const REWARD_ID = __ENV.TEST_DATA_ID;
export default function() {
const userId = generateUUID();
const fundingId = generateUUID();
const payload = JSON.stringify({
fundingId: fundingId,
items: [
{
rewardId: REWARD_ID,
optionId: null,
quantity: 1,
}
],
});
const params = {
headers: {
'Content-Type': 'application/json',
'X-User-Id': userId,
},
};
const response = http.post(
`${BASE_URL}/internal/rewards/reserve-stock`,
payload,
params
);
if (response.status === 200) {
successDuration.add(response.timings.duration);
} else if (response.status === 409) {
failDuration.add(response.timings.duration);
}
check(response, {
'status is 200 or 409': (r) => r.status === 200 || r.status === 409,
'response has body': (r) => r.body && r.body.length > 0,
});
}
현재 상황 테스트 결과
TPS 및 리소스 사용률
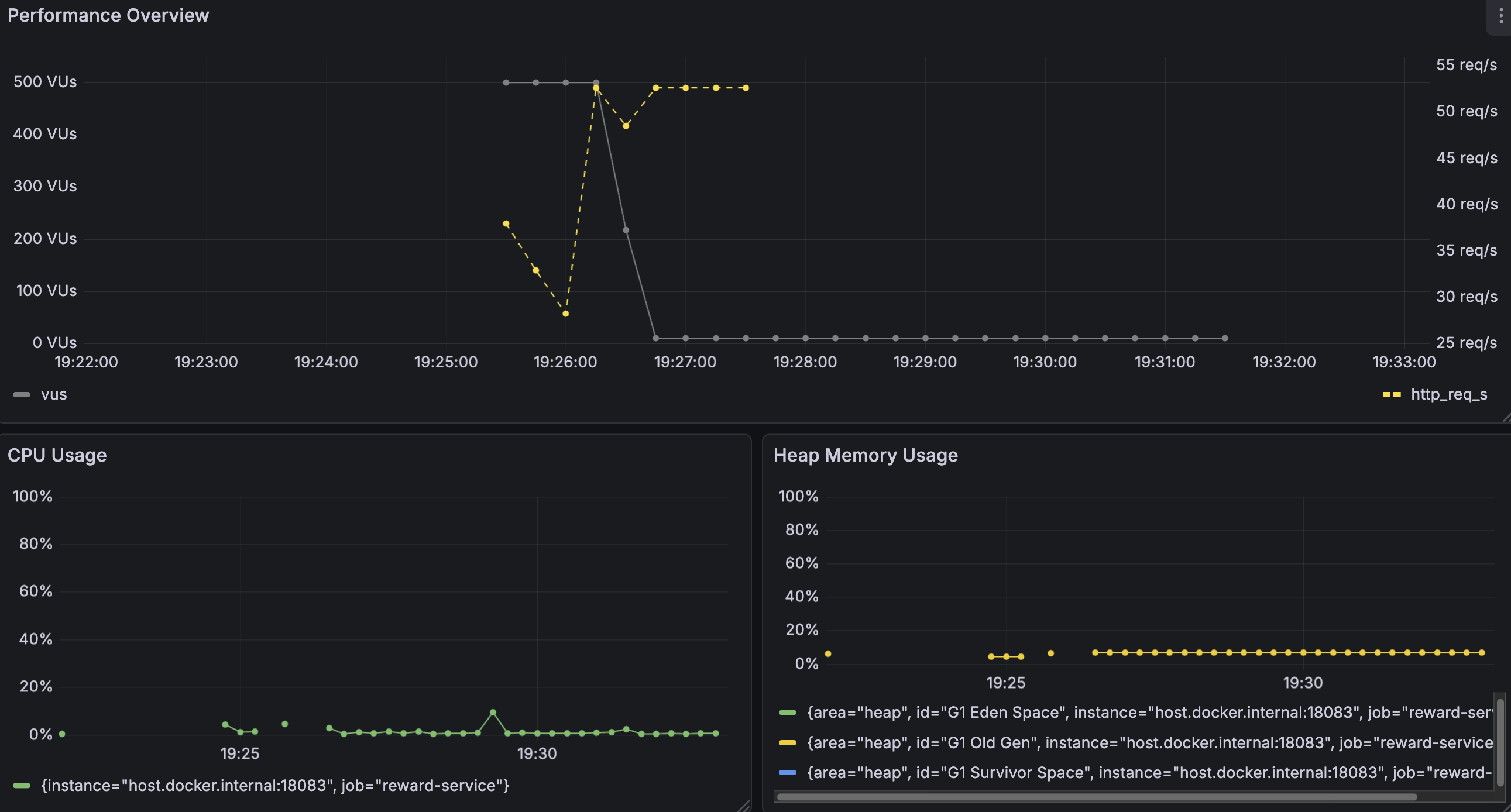
VU 500명으로 테스트를 시작했는데, 시스템이 부하를 전혀 감당하지 못했다.
TPS는 30~55 req/s 사이를 오가다가 VU가 10명까지 급감했고, 대부분의 요청이 타임아웃으로 종료됐다.
CPU와 메모리 사용률은 5~10% 수준으로 대부분 유휴 상태였다.
즉, CPU가 실제 연산 처리보다는 락 대기에 대부분의 시간을 소비하고 있음을 의미하며, 메모리는 병목이 아니라는 것을 확인했다.
HikariCP 지표
- 총 커넥션(파란색): 10개로 고정
- 활성 커넥션(초록색): 10개 모두 사용 중
- 유휴 커넥션(노란색): 거의 0개 (여유 없음)
- 대기 스레드(주황색): 최대 190개 (커넥션 부족)
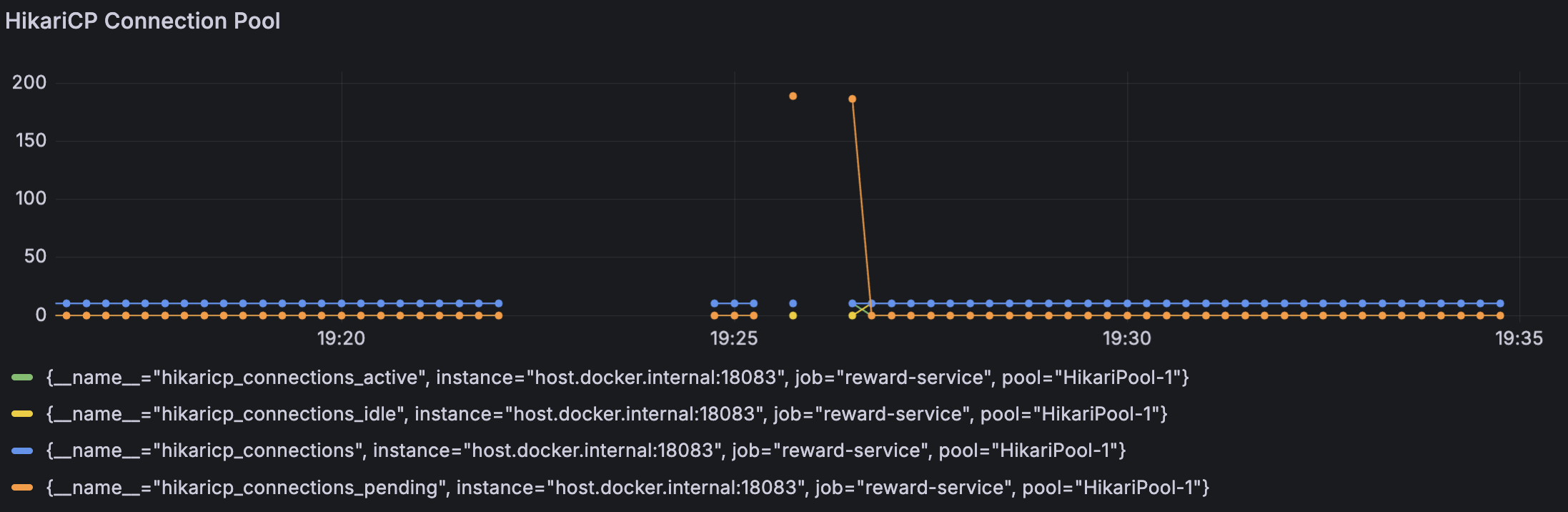
HikariCP 커넥션 풀 그래프에서 병목의 원인이 확인된다.
대기 중인 스레드가 190개까지 급증하며 커넥션이 부족한 현상이 발생했다.
총 커넥션은 10개로 고정되어 있고, 유휴 커넥션은 거의 0에 가까워 모든 커넥션이 항상 사용 중이었다.
이는 HikariCP 커넥션 갯수가 10개(기본값)로 설정되어 있어, 500명의 동시 요청을 감당할 수 없었기 때문이다.
문제 해결 - HikariCP 커넥션 풀 설정(50개)
비관적 락을 사용하는 경우, 하나의 트랜잭션이 락을 획득한 상태로 오랜 시간 DB 커넥션을 점유하게 된다.
이 상황에서 동시에 많은 요청이 들어오면, 커넥션이 빠르게 소진되어 나머지 요청들은 커넥션을 할당받지 못해 대기하게 된다.
즉, 500명의 사용자가 동시에 요청을 보내는 상황에서 커넥션 풀이 10개로 제한되어 있다면, 락으로 인해 점유된 커넥션이 해제되기를 기다리는 요청이 급격히 늘어나며 전체 처리량이 감소하게 된다.
TPS 및 리소스 사용률
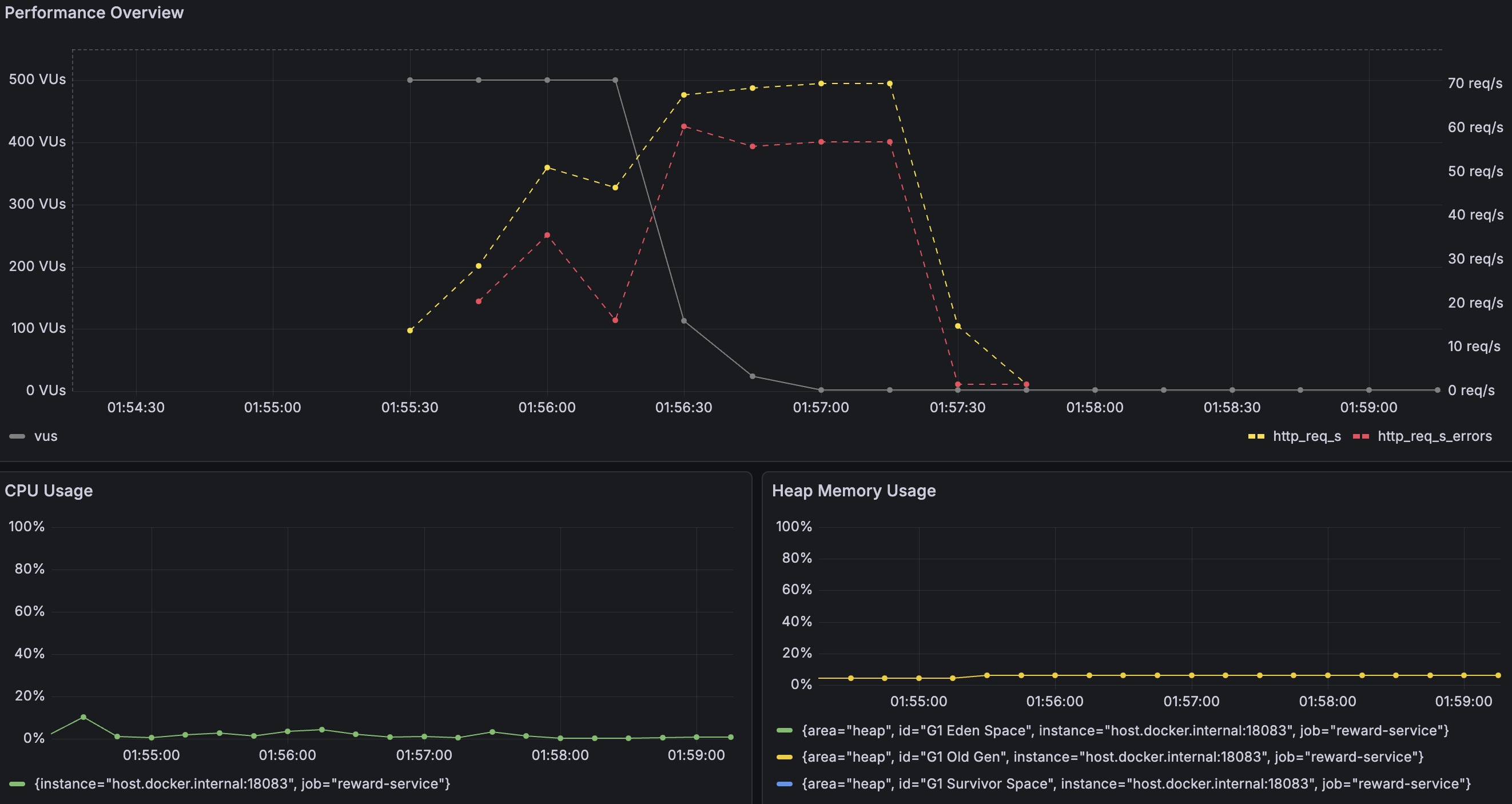
이전과 비교했을 때 TPS는 10~70 req/s 사이를 오가며 이전보다 최대치가 20 req/s 정도 높아졌지만, 에러율도 최대 60 req/s까지 증가하며 여전히 불안정했다.
VU가 500명에서 급격히 감소하기 시작해 거의 0명으로 떨어졌고, 대부분의 요청이 여전히 타임아웃으로 종료됐다.
CPU와 메모리 사용률은 커넥션 풀을 50개로 늘렸음에도 큰 변화가 없다.
HikariCP 지표
- 총 커넥션(파란색): 50개로 증가 (이전 10개)
- 활성 커넥션(초록색): 최대 50개까지 사용
- 유휴 커넥션(노란색): 0~30개 사이 변동 (이전 0개 고정)
- 대기 스레드(주황색): 최대 150개 (이전 190개에서 감소)
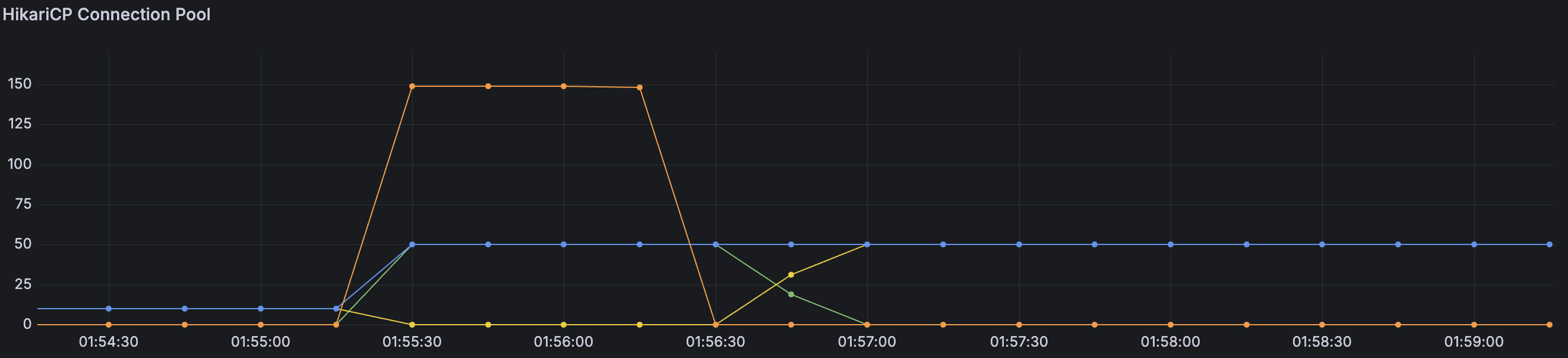
HikariCP 커넥션 풀을 50개로 증가시켰지만, 병목은 여전히 해결되지 않았고, 대기 중인 스레드가 여전히 150개까지 급증했다.
이전보다는 줄었지만, 활성 커넥션이 50개 모두 사용 중이고 유휴 커넥션은 0에 가까워 커넥션 부족 현상이 지속되었다.
즉, 커넥션을 50개로 늘렸음에도 500명의 동시 요청을 감당하기엔 부족했고, 비관적 락으로 인한 긴 트랜잭션 시간이 근본적인 문제였다.
문제 해결 - 분산락
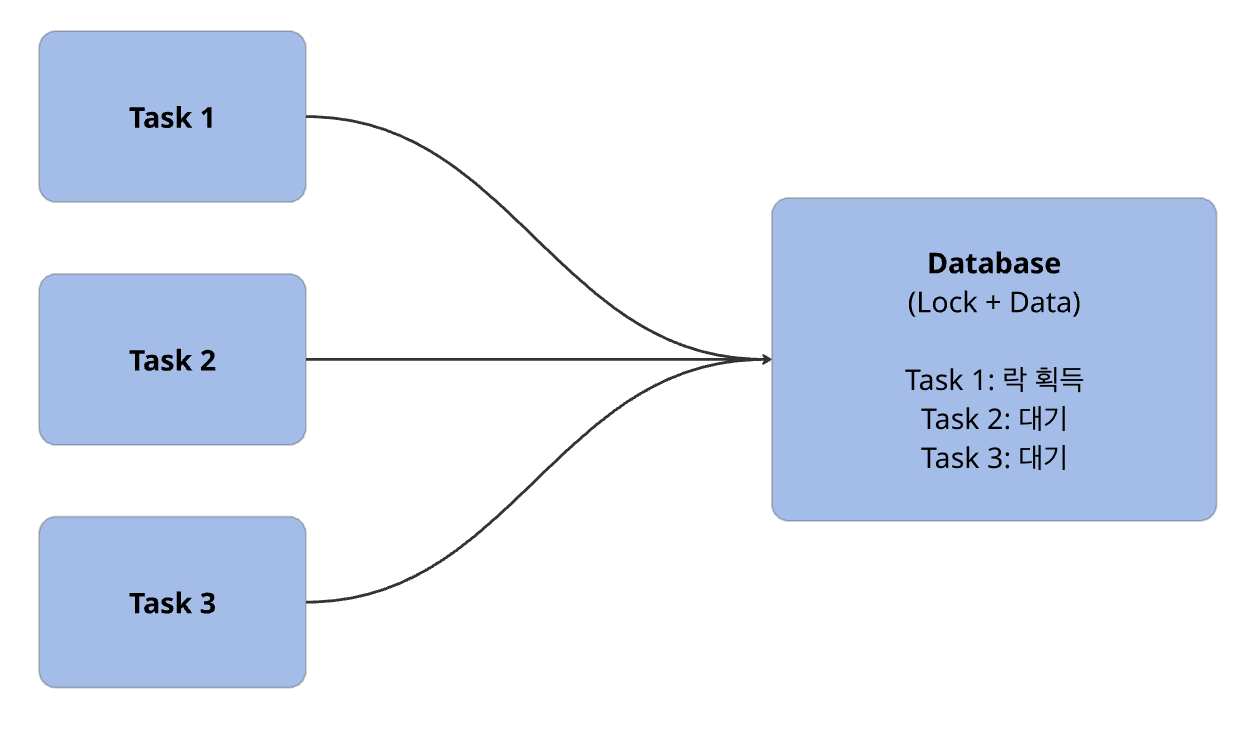
커넥션 갯수를 늘려봤지만 근본적 문제인 비관적 락의 긴 트랜잭션 시간으로 커넥션 풀 크기와 관계없이 동시 처리량이 제한됐다.

이를 해결하기 위해 비관적 락을 사용하면 안 된다 판단하여 낙관적 락과 분산락을 고려하고 있었다.
먼저 낙관적 락은 충돌이 적을 것이라 가정하고, 충돌 발생 시 재시도하는 방식이다.
하지만 클라우드 펀딩과 티켓팅에서는 한정된 재고를 두고 경쟁하기 때문에 충돌이 빈번하게 발생하고, 재시도 정책이 오히려 독이다.
마지막으로 가장 큰 문제는 확장성을 고려했을 경우, 낙관적 락과 비관적 락은 물리적으로 분리된 DB간의 일관성을 보장할 수 없다.
분산 락 선택 이유
충돌이 빈번한 상황에서 DB 커넥션 병목 없이 동시성 제어를 안정적으로 적용하기 위해 Redis 기반 분산 락을 선택했다.
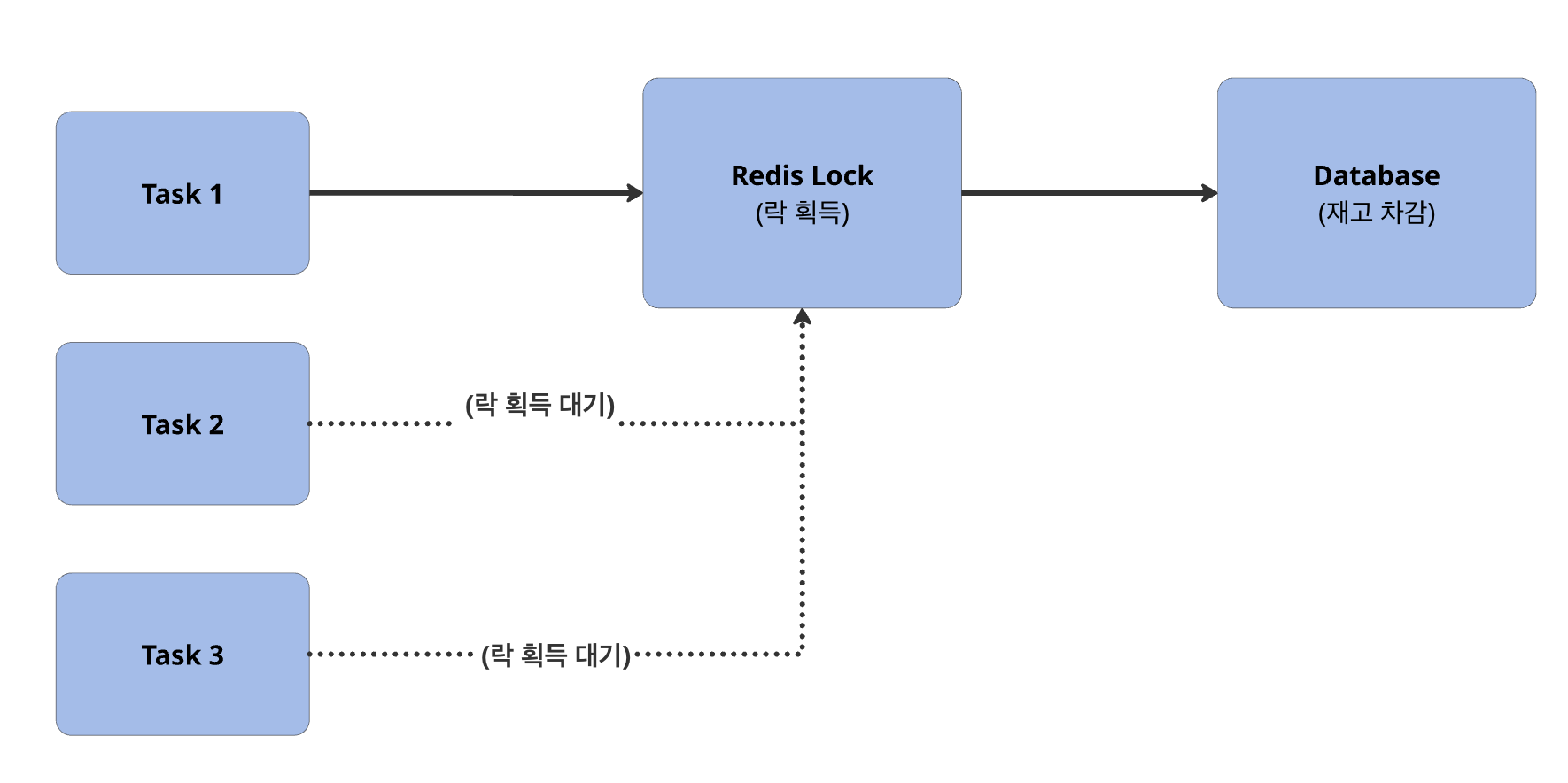
비관적 락은 락을 잡는 동안 DB 커넥션을 함께 점유해, 동시 요청이 몰리면 커넥션 풀 고갈 → 대기 스레드 증가 → TPS 급감으로 이어졌다.
따라서 락 경합이 많은 상황에서도 처리량을 유지하기 위해 Redis 기반 분산 락으로 락 구간을 DB 밖으로 분리했다.
Redisson 선택 이유
Redis 기반 분산 락을 직접 구현할 수도 있었지만, 락의 원자성, TTL 관리, 예외 상황 처리 등을 모두 직접 책임지는 것은 리스크가 크다고 판단했다. Redisson은 이러한 복잡성을 잘 추상화하면서도 안정적인 분산 락을 제공한다.
타임아웃을 설정하여 데드락 방지
tryLock(waitTime, leaseTime) 형태로 락 대기 시간과 만료 시간을 명시할 수 있다.
특히 락을 해제하지 못하고 애플리케이션이 비정상 종료가 되어도 leaseTime 후 자동으로 락이 해제되어 데드락을 방지할 수 있다.
스핀 락을 사용하지 않는다
일반적인 스핀 락은 락 획득을 위해 지속적으로 Redis를 폴링해야 하지만, Redisson은 Redis Pub/Sub을 활용한다.
락이 해제되면 대기 중인 스레드에게 알림을 보내 즉시 재시도하도록 하여 불필요한 폴링과 CPU 낭비를 줄였다.
Lua 스크립트 사용
락 획득, 해제, TTL 설정을 개별 명령으로 실행하면 중간에 실패할 경우 일관성이 깨질 수 있다.
Redisson은 이러한 연산들을 Lua 스크립트로 묶어 원자적으로 실행하여 데이터 정합성을 보장한다.
하이퍼커넥트 분산락 구현 블로그에서 쉽게 설명하여 원리 이해해 큰 도움이 됐습니다.
분산 락 구현
분산 락 적용을 위해 서비스를 두 개로 분리했다.
- RewardStockService - 분산 락 관리
- 락 획득/해제 로직 담당
- RewardStockTransactionService - 트랜잭션 처리
- 실제 재고 차감/복원 로직
- @Transactional 어노테이션으로 트랜잭션 관리
이렇게 분리한 이유는 Spring AOP 프록시 문제 때문이다.

Spring은 @Transactional이 붙은 클래스에 대해 프록시 객체를 생성한다.
이 프록시는 메서드 실행 전후로 트랜잭션 시작/커밋 로직을 추가하는 방식으로 동작한다.
또한 프록시는 외부에서 호출될 때만 동작하기 때문에, 같은 클래스 내부에서는 @Transactional 메서드를 호출하면 프록시를 거치지 않고 실제 객체의 메서드가 직접 호출되어 때문에 트랜잭션이 시작되지 않는다. 이를 해결하기 위해 트랜잭션 로직을 별도 서비스로 분리했다.
락 획득 → 트랜잭션 → 락 해제
분산 락과 트랜잭션의 실행 순서를 보장하기 위해 다음과 같은 구조로 구현했다.
// RewardStockService
private T executeWithLock(String lockKey, Supplier action) {
RLock lock = redissonClient.getLock(lockKey);
try {
// 락 획득 시도
boolean acquired = lock.tryLock(5, 3, TimeUnit.SECONDS);
if (!acquired) {
throw new RewardException(STOCK_LOCK_TIMEOUT);
}
// 트랜잭션 서비스 호출
return action.get();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RewardException(STOCK_LOCK_INTERRUPTED);
} finally {
// 락 해제
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}락을 먼저 획득한 후 트랜잭션을 시작하고, 트랜잭션 커밋이 완료된 후에 락을 해제하도록 구현했다.
만약 락 획득에 실패하면 예외를 던져 작업을 중단하고, 인터럽트 에러가 발생하면 스레드의 인터럽트 상태를 복원한 후 예외를 던진다.
락 키 설계
리워드별로 독립적인 락 사용.
String lockKey = "reward:stock:" + rewardId;서로 다른 리워드는 동시에 처리할 수 있으면서도, 같은 리워드에 대한 동시 접근은 순차적으로 처리하여 재고 정합성을 보장했다.
DB 조회 방식 변경
기존에는 비관적 락을 사용해 조회 시점에 락을 걸었다.
// 기존 비관적 락
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT r FROM Rewards r WHERE r.id = :id")
Optional findByIdWithLock(@Param("id") UUID id);이제는 분산 락으로 동시성을 제어하기 때문에 DB 락은 더 이상 필요하지 않아 findById로 조회하여 커넥션 점유 시간을 최소화 했다.
성능 테스트
TPS 및 리소스 사용률
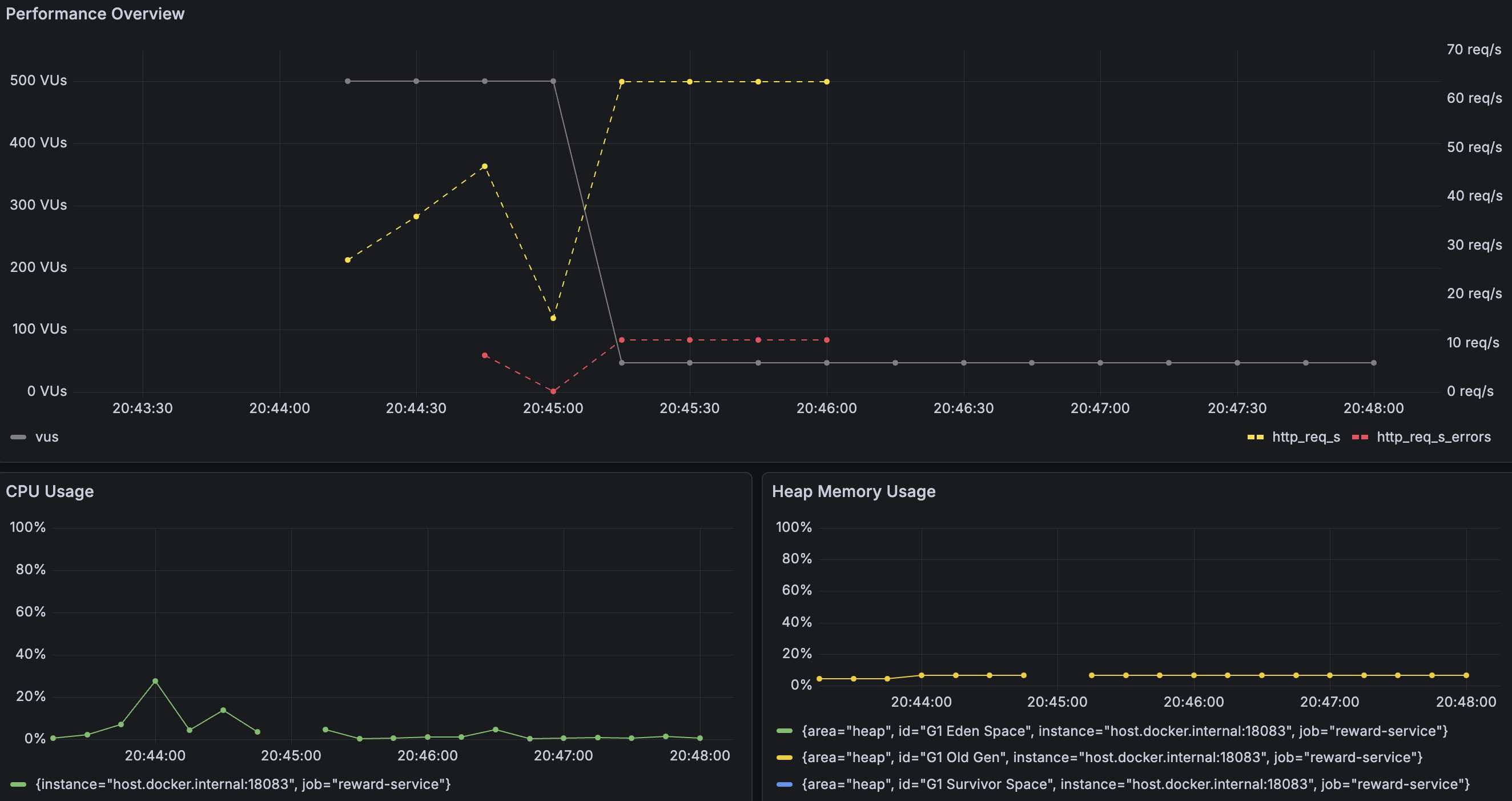
분산 락 적용 후 TPS는 60~70 req/s 수준으로 유지되었고, 처리량 자체는 비관적 락과 큰 차이가 없어 실망했다.
하지만 안정성 측면에서 봤을 때는 큰 변화가 있었다. 비관적 락 환경에서는 DB 커넥션 부족으로 인해 요청의 50~60%가 타임아웃으로 실패했지만, 분산 락 적용 후 실패율은 약 14%까지 감소했다.
분산 락은 동일 리워드에 대한 요청을 순차적으로 처리하기 때문에 처리량에서는 큰 이점을 보지 못했던 거 같다.
그래도 대기 중인 요청들이 커넥션 부족으로 타임아웃되지 않고 끝까지 처리된다는 점에서 사용자 경험은 크게 개선할 수 있었다.
HikariCP 지표
- 총 커넥션(파란색): 10~11개
- 활성 커넥션(초록색): 0~1개
- 유휴 커넥션(노란색): 9~10개
- 대기 스레드(주황색): 0개

HikariCP 지표를 보면서 흥미로운 점이 있었다. 커넥션 풀의 최대 크기는 50개로 설정되어 있었지만, 분산 락 적용 후 실제로 사용된 커넥션 수는 10개 정도만 사용됐다.
이유는 분산 락이 Redis에서 동시성을 제어하면서, DB 트랜잭션이 필요한 순간에만 짧게 실행되도록 구조가 변경되었기 때문이다.
비관적 락 환경에서는 50개의 커넥션이 모두 점유되며 대기 스레드가 최대 150개까지 급증했지만, 분산 락 환경에서는 활성 커넥션 수가 안정적으로 유지되었고 대기 스레드는 0개로 존재하지 않았다.
즉, 커넥션 풀을 50개로 확장했음에도 실제 병목은 DB가 아니라 락 경합에 있었고, 분산 락을 통해 DB 커넥션 경합 자체를 제거할 수 있었다.
마무리
분산 락 도입으로 에러율이 50~60%에서 약 14%까지 감소하여 시스템 안정성이 개선되었다.
TPS는 60~70 req/s 수준으로 비관적 락과 큰 차이는 없었지만, 그라파나 지표를 통해 DB 커넥션 병목을 확인하여 개선할 수 있었다.
또한 분산 락의 특성상 요청이 순차적으로 처리되기 때문에, TPS가 크게 개선되지 않았던 이유도 납득할 수 있었다.
또한 성능 개선은 단순히 락 방식을 바꾼다고 개선되는 게 아닌, 요청 처리 흐름 중 병목 지점을 명확히 확인하고 병목을 줄이는 방향으로 접근해야 한다는 점을 배웠다.
마지막으로, 이번 테스트를 통해 병목 지점은 CPU가 아니라 DB 커넥션과 대기에서 발생한다는 것을 확인했고, 분산 락을 통해 그 문제를 완화할 수 있었다.
여기서 TPS를 더 끌어 올리려면 락 매커니즘 보다는 요청이 몰리는 구간을 어떻게 분산할지, 처리 흐름을 어떻게 바꿀지에 대한 고민이 필요하다는 점도 함께 알게 되었다.
'개발' 카테고리의 다른 글
| 분산 트랜잭션 실패 시 데이터 정합성 보장하기 (0) | 2026.01.24 |
|---|---|
| 재고 차감 시 발생하는 동시성 이슈 해결 - 비관적 락 (1) | 2025.12.21 |
| MSA 환경에서 이벤트 데이터 정합성 문제를 해결하기 위한 아웃박스 패턴 적용 (1) | 2025.12.13 |
| 프로젝트 아키텍처 설계 - 레이어드? 헥사고날? (5) | 2025.08.12 |
| Querydsl 서브쿼리 중복 코드 개선 - 의존성 분리 (2) | 2025.08.11 |