

현재 구조는 통계 데이터가 변경될 때마다 mongoTemplate을 사용해 MongoDB에 직접 접근하여 값을 수정하는 방식이다.
이 방식은 간단하고 빠르게 구현할 수 있지만, 트래픽이 몰리는 상황에서는 DB에 과도한 부하가 발생하여 연결이 불안정해질 수 있다.
이를 개선하는 방법으로, 데이터 변경 시 즉시 MongoDB에 반영하지 않고, Redis에 먼저 캐싱한 뒤 일정 시간마다 MongoDB로 동기화 하는 방법을 사용할 것이다.
개선 전 설계
1차 도식화

우선 위 글을 바탕으로 도식화를 한 상황이다.
핵심은 Redis 캐시 도입으로 MongoDB에 직접적인 읽기/쓰기 요청을 줄여, 트래픽을 분산시킬 수 있다.
2차 도식화
Redis 캐싱 과정을 더 구체적으로 도식화하면 다음과 같다.
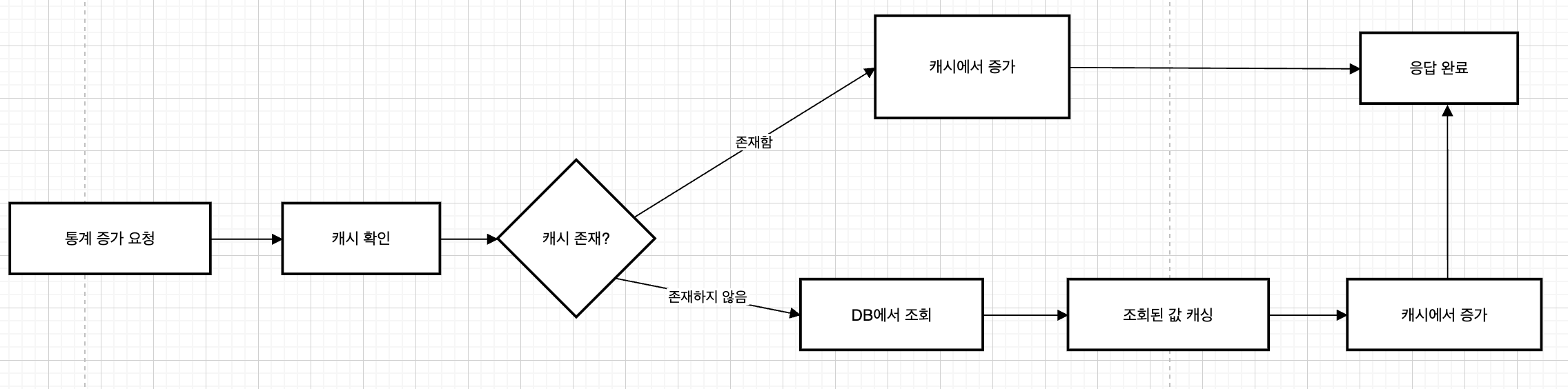
도식화된 그림을 바탕으로 현재 내 프로젝트에 적용하면 다음과 같을 것이다.
service.increment -> repository.increment -> boardboardStatsCommandCache.increment
service.increment
단순히 행위만을 표현하고 구체적인 부분은 infrastructure에 책임을 넘긴다.
repository.increment 여기선 두 가지 방법이 있었다
1. 캐시 클래스에 레포지토리 클래스 주입
2. 캐시 클래스의 increment 메서드 인자를 Function으로 받아 fallback 전략 사용
결론적으로 2번째 방법을 채택했다.
이유는 앞서 게시글과 통계를 캐싱했을 때도 Function을 활용해 fallback 전략을 사용했었고,
리팩토링인 만큼 책임분리를 최대한 신경 썼다.
캐시 클래스 구현
서비스 계층은 비즈니스 로직만 갖고있어, 데이터가 어떤 방식으로 저장되거나 업데이트되는지 알 필요가 없다.
Redis 캐시가 도입되더라도 서비스 계층의 코드는 변경되지 않아 별도 수정은 없었다.
레포지토리 계층 또한 MongoDB에 직접 접근하는 대신, 새로 구현할 캐시 클래스의 메서드를 호출하여 처리할 것이기 때문에 내부 구현 방식만 캐시 클래스를 호출하도록 변경하면 된다.
BoardStatsCommandCache
private static final String HASH_PREFIX = "qnaStats:";
private static final Duration CACHE_TTL = Duration.ofHours(1);
private final HashOperations<String, String, String> hashOperations;
/**
* 좋아요수 증가
* fallBack 전략으로 캐시에 없을 경우 mongoDB 조회
*/
public void incrementLikeCount(String qnaId, Function<String, Optional<BoardStats>> mongoFallback) {
String key = HASH_PREFIX + qnaId;
if (Boolean.FALSE.equals(hashOperations.getOperations().hasKey(key))) {
BoardStats boardStats = mongoFallback.apply(qnaId).orElseThrow(
() -> new QnaNotFoundException(ErrorCode.QNA_NOT_FOUND)
);
cacheStats(boardStats);
}
hashOperations.increment(key, "likeCount", 1);
hashOperations.getOperations().expire(key, CACHE_TTL);
}
/**
* 통계 캐시 저장
*/
public void cacheStats(BoardStats stats) {
String key = HASH_PREFIX + stats.getQnaId();
hashOperations.putAll(key, mapToHash(stats));
hashOperations.getOperations().expire(key, CACHE_TTL);
}incrementLikeCount 구현 코드에서 왜 fallBack 전략과 Function 인터페이스를 사용한 이유를 알 수 있다.
mongoFallback.apply 호출로 캐시 클래스가 직접 MongoDB에 의존하지 않고 필요할 때만 주입을 받을 수 있기 때문이다.
또한 Redis Hash는 문자열 형태의 key:value 쌍만 저장이 가능하기 때문에 다음과 같이 객체를 Map으로 변환해주는 mapToHash가 필요하다.
private Map<String, String> mapToHash(BoardStats boardStats) {
String answerCount = Optional.ofNullable(boardStats.getAnswerCount()).orElse(0L).toString();
String replyCount = Optional.ofNullable(boardStats.getReplyCount()).orElse(0L).toString();
String likeCount = Optional.ofNullable(boardStats.getLikeCount()).orElse(0L).toString();
String viewCount = Optional.ofNullable(boardStats.getViewCount()).orElse(0L).toString();
return Map.of(
"answerCount", answerCount,
"replyCount", replyCount,
"likeCount", likeCount,
"viewCount", viewCount
);
}현재 도메인 규칙은 질문은 좋아요를 받을 수 없고 답변의 경우 댓글은 달릴 수 있지만 답변은 달릴 수 없어 redis hash에 그대로 저장하게 된다면 null로 저장될 것이다.
저장하는 것까지는 문제가 되지 않지만, 객체형식으로 역직렬화할 때 null 관련 에러가 발생할 가능성이 있어 이를 방지하기 위해 null일 경우 0으로 저장했다.
BoardStatsRepositoryImpl
@Override
public void incrementLikeCount(String boardId) {
boardStatsCommandCache.incrementLikeCount(
boardId,
this::findBoardStatsByQnaId
);
}incrementLikeCount의 두 번째 인자값으로 Function 타입을 받고있기 때문에 위와 같이 함수 형태로 넘겨주어야 한다.
동기화 설계
동기화 시 Redis Hash에 저장된 모든 데이터를 MongoDB에 동기화하면 이미 DB에 반영된 데이터도 TTL이 남아있어 변경되지 않은 데이터도 다시 중복으로 MongoDB에 저장되는 일이 발생할 수 있다.
어차피 변경되지 않았기 때문에 데이터 무결성에 문제가 없을 수 있지만, 잠재적 문제를 알고서 그냥 안고 가는 것보다 안정적으로 구현하기 위해 다음과 같은 플로우로 구현할 것이다.
1. 변경된 key를 관리하기 위한 Set추가
2. flush 시점에 Set에 있는 key만 조회 및 동기화
3. flush 완료 후 Set 초기화
이를 간단하게 도식화 하면 다음과 같다.

구현
설계에서 봤듯이 변경된 key를 관리하기 위한 Set을 선언해준다.
이때 set은 HashSet이 아닌 ConcurrentHashMap.newKeySet();으로 멀티 쓰레딩 환경에서 안전하게 관리할 것이다.
이유는 여러 쓰레드가 동시에 key를 추가하는 일이 생기면 쓰레드가 충돌하거나 데이터 손실이 발생할 수 있기 때문이다.
예를들어, 좋아요 수 증가와 조회 수 증가 요청이 동시에 들어와도, 안전하게 추가할 수 있어야 된다.
BoardStatsCommandCache
private final Set<String> modifiedKeys = ConcurrentHashMap.newKeySet();
/**
* 조회수 증가
* fallBack 전략으로 캐시에 없을 경우 mongoDB 조회
*/
public void incrementViewCount(String qnaId, Function<String, Optional<BoardStats>> mongoFallback) {
updateStats(qnaId, "viewCount", 1, mongoFallback);
}
/**
* 몽고디비에 동기화
*/
public void flushCache(Function<BoardStats, BoardStats> mongoSaveFunction) {
if (modifiedKeys.isEmpty()) {
return;
}
Set<String> flushKey = new HashSet<>(modifiedKeys);
modifiedKeys.clear();
for (String currentQnaId : flushKey) {
try {
String redisKey = HASH_PREFIX + currentQnaId;
Map<String, String> cachedStats = hashOperations.entries(redisKey);
if (cachedStats == null || cachedStats.isEmpty()) {
continue;
}
BoardStats boardStats = convertHashToBoardStats(currentQnaId, cachedStats);
mongoSaveFunction.apply(boardStats);
} catch (Exception e) {
modifiedKeys.add(currentQnaId);
}
}
}앞에서 말했듯이 ConcurrentHashMap.newKeySet()으로 동시성 문제에도 안전하게 구현했다.
플러쉬도 캐싱과 같이 Function 인터페이스를 활용해 의존성을 분리했다.
플러시 과정에서 에러가 발생하면 동기화가 실패할 수 있다.
이때 다음 10분 주기 재캐싱을 기다리면 될 것 같지만, TTL 만료로 인해 캐시에 증감된 데이터가 삭제될 위험이 있다.
또한 flushCache 내의 modifiedKey.clear() 로직 때문에 변경된 키 목록도 사라져 추적할 수 없다.
이를 해결하기 위해 try-catch 문으로 에러 발생 시 다시 추적할 수 있도록 구현했고, 다음 주기에 변경된 키에 대해서 다시 동기화를 시도하기 때문에 데이터 무결성을 유지할 수 있다.
BoardStatsRepositoryImpl
@Override
public void incrementAnswerCount(String boardId) {
boardStatsCommandCache.incrementAnswerCount(
boardId,
this::findBoardStatsByQnaId
);
}
@Override
public void flushCache() {
boardStatsCommandCache.flushCache(this::save);
}레포지토리 계층에서는 단순히 flushCache를 호출하도록 하고 별도 스케줄러를 관리하는 클래스를 만들어 boardStatsRepository.flushCache() 메서드를 호출하게 설계했다.
이렇게 설계하면 BoardStatsRepositoryImpl는 데이터 접근 로직에만 집중할 수 있게 된다.
BoardStatsScheduler
@Component
@RequiredArgsConstructor
public class BoardStatsScheduler {
private final BoardStatsRepository boardStatsRepository;
@Scheduled(fixedDelay = 600000) // 10분마다 동기화
public void flushToMongo() {
boardStatsRepository.flushCache();
}
}fixedDelay 옵션을 사용해 이전 작업이 완료된 후 10분 뒤에 다음 작업을 실행하도록 설정했다.
fixedRate와 달리 작업 실행 시간이 길어져도 겹치지 않아 안전하게 동기화할 수 있다.
또한 스케줄링 로직을 독립적으로 관리해 유지보수에 유리하다.
성능테스트
테스트 조건

성능 개선 전

성능 개선 후

결과
평균 응답 시간 1022ms → 485ms 약 53% 감소
처리량 129.6/sec → 167.2/sec로 약 30% 증가
비동기 시스템 도입으로 요청이 들어왔을 때 바로 데이터베이스로 접근하는 것이 아닌 캐시에서 먼저 조회 후 캐시미스시 DB로 접근하게 설계하여 시스템 안정성을 높였습니다.
'개발' 카테고리의 다른 글
| 프로젝트 아키텍처 설계 - 레이어드? 헥사고날? (5) | 2025.08.12 |
|---|---|
| Querydsl 서브쿼리 중복 코드 개선 - 의존성 분리 (2) | 2025.08.11 |
| 개발 환경 통일을 위한 Docker Compose 도입 (5) | 2025.07.30 |
| Redis 캐시 구조 개선 : Redis Hash 적용하기 (1) | 2025.06.24 |
| MongoDB 도큐먼트 분리와 Redis 캐싱으로 게시판 성능 최적화 (2) | 2025.05.26 |